Table of Contents
- What is Accuracy in Machine Learning?
- Why Accuracy Is Misleading in Machine Learning Models
- Accuracy vs Precision vs Recall in Machine Learning
- Class Imbalance in Machine Learning
- Business-Aligned Metrics in Machine Learning
- Offline vs Real-World Model Evaluation
- Why Data Quality Matters More Than Model Complexity
- Common Data Quality Issues in Machine Learning
- Garbage In, Garbage Out in ML Systems
- Real-World ML Failure Pattern
- How to Evaluate Machine Learning Models Correctly
- Key Takeaways
- Conclusion
What is Accuracy in Machine Learning?
Accuracy in machine learning is the percentage of correct predictions made by a model out of all predictions.
While it is simple to understand, accuracy becomes misleading in imbalanced datasets and real-world systems because it does not reflect how well a model performs on important or rare cases.
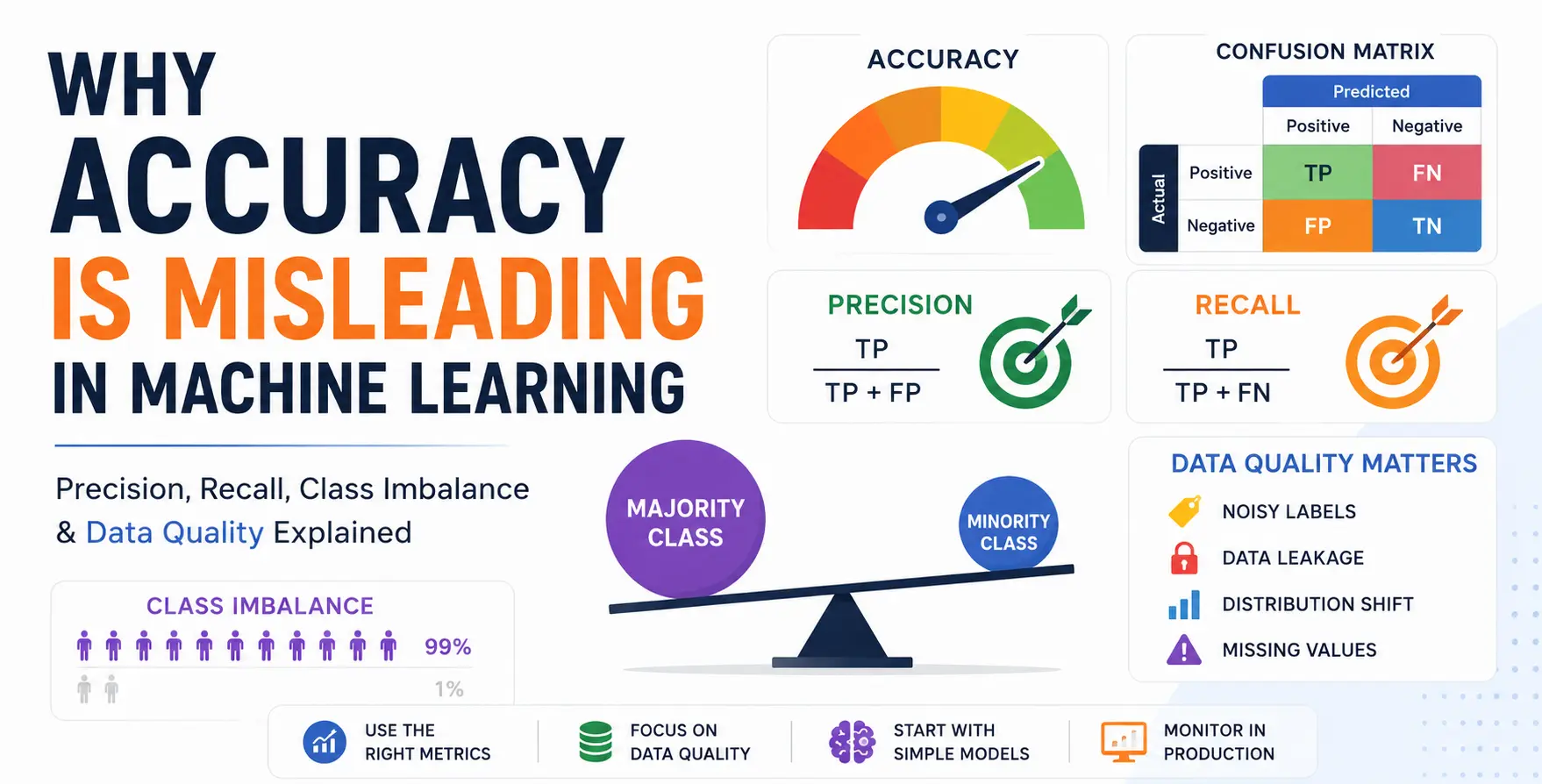
Why Accuracy Is Misleading in Machine Learning Models
Accuracy assumes that all prediction errors have equal importance. In practice, this assumption fails in almost every real-world use case.
For example, in fraud detection or medical diagnosis, missing a critical case is far more costly than making a minor incorrect prediction. Accuracy ignores this difference and presents an overly simplified view of performance.
As a result, models optimized only for accuracy often perform poorly where it actually matters.
Accuracy vs Precision vs Recall in Machine Learning
To properly evaluate machine learning models, it is essential to understand the difference between accuracy, precision, and recall.
- Precision measures how many predicted positive cases are actually correct
- Recall measures how many actual positive cases the model successfully identifies
Why this matters
In real-world systems, improving precision often reduces recall, and vice versa. The correct balance depends on the use case:
- Fraud detection requires high recall to catch as many fraudulent cases as possible
- Spam filtering requires high precision to avoid misclassifying legitimate messages
- Medical diagnosis prioritizes recall to avoid missing critical conditions
Accuracy does not capture this tradeoff, making it an incomplete metric for model evaluation.
Class Imbalance in Machine Learning: Why Accuracy Fails
Class imbalance occurs when one class significantly outnumbers others. This is common in many real-world applications such as fraud detection, anomaly detection, and recommendation systems.
Why accuracy breaks under class imbalance
When datasets are imbalanced, models tend to favor the majority class because it improves overall accuracy. This leads to high accuracy scores while completely ignoring minority classes.
Example
If 99% of data belongs to one class, a model can achieve 99% accuracy simply by predicting that class every time, without learning anything meaningful.
Better evaluation metrics for imbalanced datasets
Instead of relying on accuracy, use:
- Precision and recall
- F1-score for balanced evaluation
- Precision-recall curves for deeper analysis
- Class-weighted loss functions during training
Business-Aligned Metrics in Machine Learning
Accuracy is a mathematical metric, but real-world systems require evaluation based on business impact.
Why business metrics matter
- In lending systems, approving a bad loan is more costly than rejecting a good one
- In recommendation systems, irrelevant suggestions reduce user engagement
- In trading systems, incorrect signals can lead to financial loss
How to evaluate models properly
- Define cost-sensitive evaluation metrics
- Measure impact on revenue, risk, or efficiency
- Align model performance with business KPIs
A model with slightly lower accuracy but better business alignment is often more valuable.
Offline vs Real-World Model Evaluation
Most machine learning models are evaluated using offline datasets. However, production environments behave very differently.
Key differences
| Offline Evaluation |
Production Environment |
| Static datasets |
Changing distributions (data drift) |
| Clean and labeled data |
Noisy and incomplete data |
| Controlled conditions |
Real-time constraints |
Why models fail in production
- Overfitting to historical data
- Ignoring temporal changes
- Hidden data leakage
- Lack of monitoring systems
Why Data Quality Matters More Than Model Complexity
A common misconception in machine learning is that better models lead to better performance. In reality, data quality has a much greater impact than model complexity.
Key insight
A simple model trained on high-quality data often outperforms a complex model trained on poor-quality data.
Why this happens
Complex models amplify noise when data is inconsistent or incorrect. Instead of learning useful patterns, they learn errors present in the dataset.
Common Data Quality Issues in Machine Learning
Noisy Labels in Machine Learning
Noisy labels occur when training data contains incorrect or inconsistent annotations.
Impact:
- Models learn incorrect relationships
- Evaluation metrics become unreliable
- Generalization performance drops
Solution:
- Validate labeling processes
- Use multiple annotators when possible
- Remove ambiguous or inconsistent samples
Feature Leakage in Machine Learning
Feature leakage happens when the model has access to information during training that would not be available during prediction.
Impact:
- Artificially high accuracy during training
- Complete failure in production
Example:
Using future information in time-series prediction tasks.
Prevention:
- Ensure strict separation of training and future data
- Validate feature availability at inference time
- Use time-aware validation methods
Distribution Shift in Machine Learning
Distribution shift occurs when the statistical properties of data change over time.
Types:
- Covariate shift (input changes)
- Concept drift (relationship changes)
Impact:
- Gradual performance degradation
- Silent model failure
Mitigation:
- Monitor data distributions
- Retrain models regularly
- Implement adaptive learning strategies
Garbage In, Garbage Out in ML Systems
If the input data pipeline is flawed, the model output will also be flawed.
- Missing or inconsistent values
- Incorrect joins or aggregations
- Duplicate or corrupted records
No model can compensate for fundamentally broken data.
Real-World ML Failure Pattern
- Dataset is collected without deep validation
- Complex models are trained
- Accuracy is optimized
- Model is deployed
- Performance drops in production
Root causes
- Incorrect evaluation metrics
- Data leakage
- Poor data quality
- Lack of monitoring and feedback loops
How to Evaluate Machine Learning Models Correctly
1. Use the right metrics
- Precision and recall
- F1-score
- Business-aligned metrics
2. Focus on data quality first
- Clean and validate datasets
- Ensure label correctness
- Remove leakage
- Track data lineage
3. Start with simple models
Use simpler models as baselines before increasing complexity. This helps identify whether improvements come from better modeling or better data.
4. Monitor models in production
- Data drift
- Prediction distributions
- Performance degradation
Continuous monitoring is essential for long-term reliability.
Key Takeaways
- Accuracy is misleading in imbalanced datasets
- Precision and recall provide better evaluation
- Business-aligned metrics are critical
- Data quality matters more than model complexity
- Most ML failures come from poor data and evaluation
Conclusion
Accuracy is easy to optimize but often misleading.
Reliable machine learning systems require meaningful evaluation metrics, high-quality data, and continuous monitoring.
Without these, even advanced models will fail in production. With them, even simple models can deliver consistent and reliable performance.